Data Mining Reveals the Way Humans Evaluate Each Other
MIT – The way we evaluate the performance of other humans is one of the bigger mysteries of cognitive psychology. This process occurs continuously as we judge individuals’ ability to do certain tasks, assessing everyone from electricians and bus drivers to accountants and politicians. The problem is that we have access to only a limited set of data about an individual’s performance—some of it directly relevant, such as a taxi driver’s driving record, but much of it irrelevant, such as the driver’s sex. Indeed, the amount of information may be so vast that we are forced to decide using a small subset of it. How do those decisions get made? Today we get an answer of sorts thanks to the work of Luca Pappalardo at the University of Pisa in Italy and a few pals who have studied this problem in the sporting arena, where questions of performance are thrown into stark relief. Their work provides unique insight into the way we evaluate human performance and how this relates to objective measures.
In recent years, the same players have also been evaluated by an objective measurement system that counts the number of passes, shots, tackles, saves, and so on that each player makes. This technical measure takes into account 150 different parameters and provides a comprehensive account of every player’s on-pitch performance. The question that Pappalardo and co ask is how the newspaper ratings correlate with the technical ratings, and whether it is possible to use the technical data to understand the factors that influence human ratings.The researchers start with the technical data set of 760 games in Serie A in the 2015-16 and 2016-17 seasons. This consists of over a million data points describing time-stamped on-pitch events. They use the data to extract a technical performance vector for each player in every game; this acts as an objective measure of his performance.
The researchers also have the ratings for each player in every game from three sports newspapers: Gazzetta dello Sport, Corriere dello Sport, and Tuttosport.
The newspaper ratings have some interesting statistical properties. Only 3 percent of the ratings are lower than 5, and only 2 percent higher than 7. When the ratings are categorized in line with the school ratings system—as bad if they are lower than 6 and good if they are 7 and above—bad ratings turn out to be three times as common as good ones.
In general, the newspapers rate a performance similarly, although there can be occasional disagreements by up to 6 points. “We observe a good agreement on paired ratings between the newspapers, finding that the ratings (i) have identical distributions; (ii) are strongly correlated to each other; and (iii) typically differ by one rating unit (0.5),” say Pappalardo and co.
To analyze the relationship between the newspaper ratings and the technical ratings, Pappalardo and co use machine learning to find correlations in the data sets. In particular, they create an “artificial judge” that attempts to reproduce the newspaper ratings from a subset of the technical data.
This leads to a curious result. The artificial judge can match the newspaper ratings with a reasonable degree of accuracy, but not as well as the newspapers match each other. “The disagreement indicates that the technical features alone cannot fully explain the [newspaper] rating process,” say Pappalardo and co.
In other words, the newspaper ratings must depend on external factors that are not captured by the technical data, such as the expectation of a certain result, personal bias, and so on.
To test this idea, Pappalardo and co gathered another set of data that captures external factors. These include the age, nationality, and club of the player, the expected game outcome as estimated by bookmakers, the actual game outcome, and whether a game is played at home or away.
When this data is included, the artificial judge does much better. “By adding contextual information, the statistical agreement between the artificial judge and the human judge increases significantly,” say the team.
Indeed, they can clearly see examples of the way external factors influence the newspaper ratings. In the entire data set, only two players have ever been awarded a perfect 10. One of these was the Argentine striker Gonzalo Higuaín, who played for Napoli. On this occasion, he scored three goals in a game, and in doing so he became the highest-ever scorer in a season in Serie A. That milestone was almost certainly the reason for the perfect rating, but there is no way to derive this score from the technical data set.
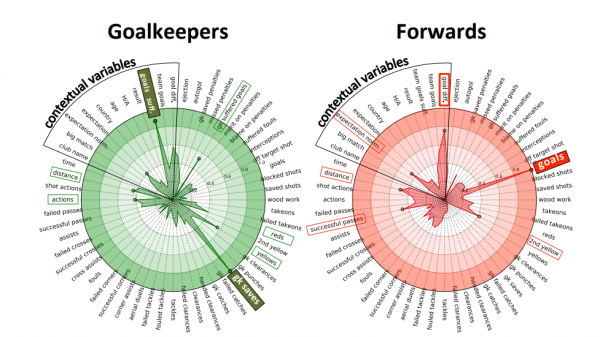
An important question is what factors the artificial judge uses to match the newspaper ratings. “We observe that most of a human judge’s attention is devoted to a small number of features, and the vast majority of technical features are poorly considered or discarded during the evaluation process,” say Pappalardo and co.
So for attacking forward players, newspapers tend to rate them using easily observed factors such as the number of goals scored; they rate goalkeepers on the number of goals conceded. Midfield players tend to be rated by more general parameters such as the goal difference.
That makes sense—human observers have a limited bandwidth and are probably capable of observing only a small fraction of performance indicators. Indeed, the team say the artificial judge can match human ratings using less than 20 of the technical and external factors.
That’s a fascinating result that has important implications for the way we think about performance ratings. The goal, of course, is to find more effective ways of evaluating performance in all kinds of situations. Pappalardo and co think their work has a significant bearing on this. “This paper can be used to empower human evaluators to gain understanding on the underlying logic of their decisions,” they conclude